

agi@hiskot.com
Skót © 2022
The Empty Chair
2025
Applied AI · Machine Learning · Ethical UX
Applied AI for predicting and preventing clinic no-shows — from data cleaning to training an interpretable model, and from risk scoring to supportive intervention design. The project uses machine learning not to label people, but to help clinics act earlier and more carefully.
At a glance
Challenge: Design an AI-powered pipeline that could identify no-show risk early, support timely reminder interventions, and keep human oversight in the loop. The underlying problem is real and significant: in the dataset, around 20% of appointments result in no-shows, affecting care, capacity, and clinic operations.
My role: Applied AI and UX designer. I worked across data preparation, interpretable machine learning, threshold logic, and intervention design. I was interested not only in prediction, but also in what should happen after the prediction — and how that next step could be useful, supportive, and human.
What I explored: How prediction, explainability, and ethical intervention design could help identify missed appointments without reducing people to risk scores. This included model selection, fairness-conscious feature choices, and a product concept that translates risk into action.
Why it matters: Used carefully, predictive systems can reduce avoidable costs for clinics while helping patients receive more timely support and treatment. In this case, the goal was not only efficiency, but earlier and more humane care.
The problem
Every empty chair in a clinic is a missed story.
A patient who did not get their scan.
A parent who could not arrange transport.
Someone who meant to come — but life got in the way.
Clinic no-shows are often discussed as wasted capacity. That is true, but it is only part of the picture. A no-show can also mean delayed treatment, a missed follow-up, or care that arrives too late. This project began with that tension: the operational problem is real, but so is the human one.
The question was not simply whether no-shows could be predicted.
The real question was whether they could be identified early enough to support people before care was missed.
Starting from support, not blame
People miss appointments for many small, stacked reasons: transport, work, childcare, anxiety, forgetting. No single column explains it. But together, those small signals can form a useful pattern. The point of the system is not to punish absence. It is to notice risk early enough to offer support.
That shaped the product from the beginning.
This was never meant to be a system that labels “unreliable patients.”
It was meant to be a system that helps clinics respond more carefully to attendance risk.
Dataset and framing
The project uses the UCI Medical Appointment No-Shows dataset from the Brazilian public healthcare system, covering 110,527 appointments. It offered a useful base for exploring the problem at scale, while still reflecting the messiness and limits of real-world healthcare data.
Some features needed to be treated with care. Scholarship status, for example, was framed as a meaningful socioeconomic signal — but not as a cause. In the project deck, it is described as something to use compassionately: as a reason to offer help, not assign blame.
Gender and Neighbourhood were excluded to reduce bias risk. SMS_received was also treated carefully. It has limitations because it may tell us more about what the clinic already did than about the patient’s original risk of missing the appointment. In that sense, it is “leaky”: it can introduce information from after the process has already started, which may make the model seem more predictive than it really is.
That distinction mattered to me.
The goal was not to use every available variable.
It was to use signals that could support a fairer and more useful intervention.
The modeling challenge
Only about one in five appointments in the dataset ends in a no-show. That makes the problem harder, but also more realistic.
A model could look successful simply by assuming most people will attend. But that would miss the point. The real challenge was not to be right in the easiest cases. It was to notice the appointments where support might be needed before care is missed.
So I did not optimize for accuracy alone.
Instead, I focused on whether the model could help surface higher-risk appointments in a meaningful order. Not because the score itself matters, but because ranking those appointments earlier makes timely action possible.
That is why PR-AUC and ROC-AUC were more useful here than plain accuracy. I needed to know whether the model could help a clinic focus attention where it may matter most.
Model choice
The final model uses Logistic Regression.
That choice was deliberate. In a healthcare context, interpretability matters. The model needed to be understandable, reproducible, and easy to inspect. Logistic Regression made it possible to see how features were influencing risk, while staying stable and lightweight enough for real-world use. In the project deck, it is described as fast, explainable, and appropriate for clinical contexts where people need to understand what the system is doing.
This project was not about building the most complex model possible.
It was about building one that could support action responsibly.
Results
The model reached an Average Precision of 0.37 and a ROC-AUC of 0.68. In the deck, those results are framed carefully: not as perfect prediction, but as good enough to trust the ranking. Average Precision performed meaningfully above the baseline prevalence of about 0.20, showing stronger concentration of true no-shows near the top of the list.
That was important.

The value of the model was not that it could know with certainty who would miss.
It was that it could create a more useful priority list than random outreach.
Threshold as a product decision
A risk score alone does not help a clinic.
The important design decision comes after the score.
In this project, the threshold was set around t ≈ 0.35, with a recall-first logic. At that setting, the model catches around 8 out of 10 likely no-shows, while keeping precision around 0.35. The reasoning behind that trade-off is simple and important: missing a no-show is costly, while sending one extra supportive reminder is relatively cheap.
That means the threshold is not just a technical leftover.
It is a service decision.
It defines how many people get extra support, how much outreach work the clinic can realistically handle, and what kind of balance is acceptable between missed risk and unnecessary outreach.
From risk to action
This is where the project becomes more than a model.
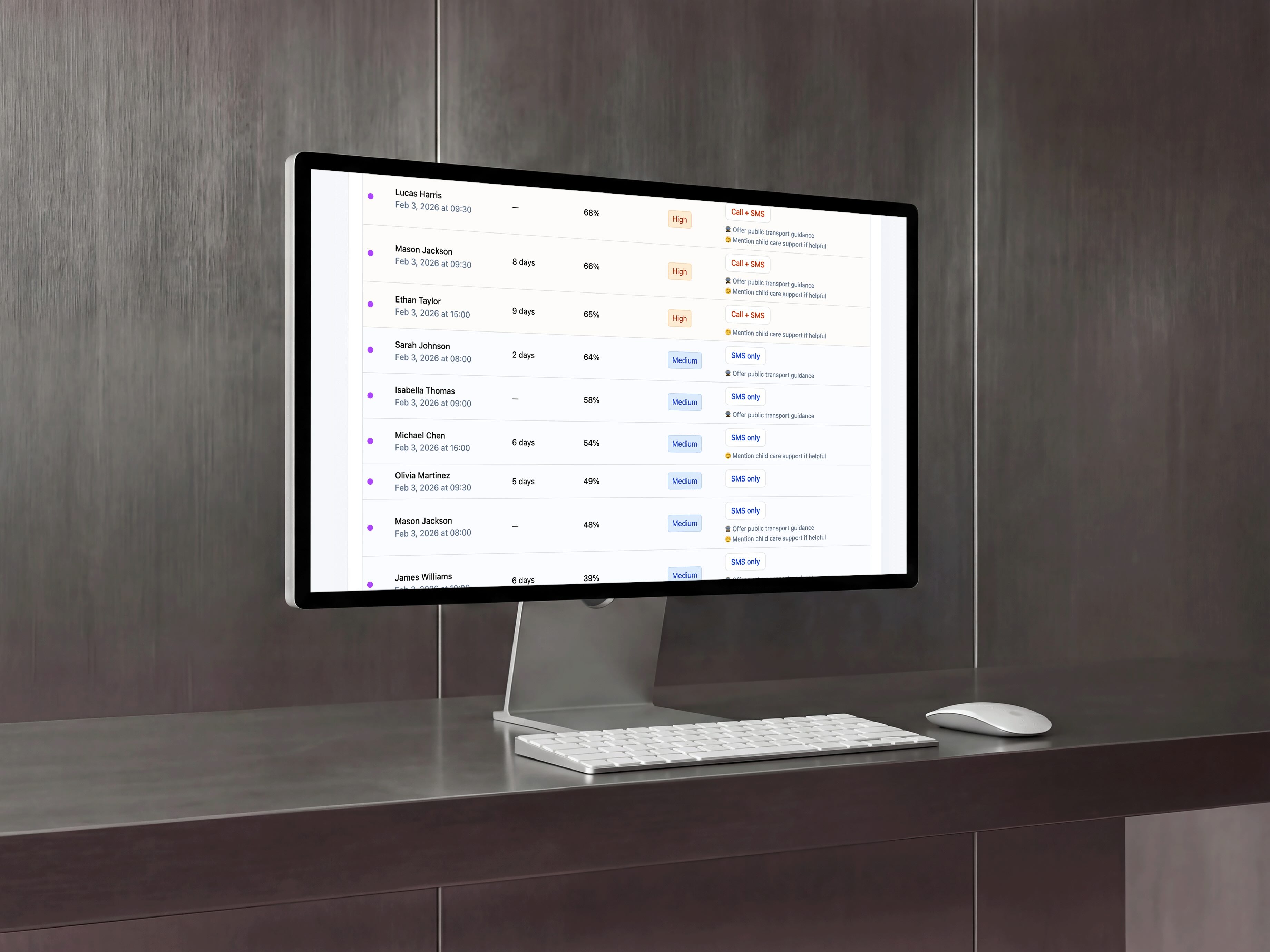
The deck maps risk into layered actions:
High risk → call + SMS
Medium risk → SMS only
Low risk → standard reminder
It also introduces operational guardrails: a daily limit on the call list, outreach matched to staff capacity, and the ability to raise or lower the threshold depending on how busy the day is. On a busy day, the threshold can rise. On a quieter day, it can lower.
That product layer matters just as much as the model itself.
Prediction only becomes valuable when it leads to a realistic next step.
Supportive intervention design
One of the most important parts of the project is what happens to a false positive.
A flagged patient does not get penalized.
They do not get overbooked against.
They do not receive stigma.
What they get is a supportive touch: a friendly SMS or call asking whether they need help with transport, whether they want to reschedule, or whether something is getting in the way. The project also proposes clear opt-out and limits on contact frequency.
That boundary was intentional.
Because the outreach is supportive, the system can tolerate more false positives.
The cost of an extra helpful reminder is low.
The cost of missing someone who needed support can be much higher.
The data pipeline
The project moves from data cleaning to product logic in a clear sequence.
First, the data was cleaned by removing invalid ages, impossible dates, and lead-time outliers. Features were kept simple and interpretable, including flags such as scholarship, hypertension, diabetes, alcoholism, disability, and sms_received, while excluding features with stronger bias risk.
Then the model was trained and evaluated using a ranking-focused strategy suited to class imbalance. Instead of trying to predict perfectly, the system was designed to surface a more useful list for intervention. The pipeline then continues beyond the model: tomorrow’s appointments are scored, compared against the threshold, translated into priority categories, and turned into an outreach list that staff can act on. The pipeline page in your deck shows exactly this shift from raw appointments to cleaned data, scoring, thresholding, action mapping, export, and outreach response.
That sequence was a big part of the project for me.
I was interested not only in the prediction itself,
but in how the signal moves through a system and becomes care.
Working prototype
To make that action layer more concrete, I built a small working Gradio web app. The prototype allows a clinic to upload a CSV of tomorrow’s appointments, generate a risk score for each row, adjust the threshold with a slider, and view suggested actions and priority flags. It also gives summary counts so staff can understand the outreach workload for the day.
This is why I think the prototype matters.
It shows that the project is not only about model performance.
It shows how the model becomes a tool.
A tiny tool, but one that helps turn tomorrow’s schedule into a more useful outreach list before care is missed. Your deck describes it in exactly those terms.
Limitations
The project is also clear about what it cannot yet see.
It does not include patient history, which is often one of the strongest signals for attendance. It does not include distance, transport time, traffic, or weather, even though those are often major reasons people miss appointments. And because the dataset is imbalanced, the work depends on ranking quality rather than a clean notion of accuracy.
Those limits matter because they shape what the model can and cannot responsibly claim.
What I would improve next
The next step would be to add stronger context: prior no-shows, attendance streaks, cancellations, ETA to clinic, weather, and public transport availability. The project also suggests removing sms_received from baseline risk and adding more explicit fairness monitoring across scholarship groups, age bands, and disability-related signals. A future model such as XGBoost could also be explored, while keeping the intervention logic and oversight carefully designed.
Reflection
This project changed the way I think about predictive systems.
The model is not the point.
The point is what becomes possible after the model.
A useful signal is only valuable when it leads to an action that is realistic, humane, and worth taking. In this case, that means earlier reminders, easier rescheduling, and better support — not blame, not hidden labels, and not punishment.
The empty chair mattered because it made the problem visible.
But the deeper design question was always the same:
How can a system notice risk early enough to help, without turning people into scores?
